
A Conjure Piglet client
用 Fennel 語言開發 Piglet 語言的 Neovim Plugin 的記錄

"Laurence, 你對 Piglet 有興趣嗎?要不要來開發 Piglet?", Arne 問我。Piglet 是他最近公開發表的新語言,當然,又是一個 Lisp 。
"好哇,該從哪邊開始呢?",我回答了他。
"你有兩個選項:
(1) 學 Emacs ,因為我已經開發好了 Emacs plugin for piglet。
(2) 開發一個 Neovim plugin。"
我選了 (2) ,於是這個專案就開始了。
很快地讀了一下 Piglet 的文件與 Emacs Plugin 之後,我的初步規畫是這樣子:
先開發 Fennel 的程式碼來處理 Piglet Dev Protocol,即先設法做到讓 Neovim 與 Piglet REPL 通話。
再將步驟 1 的程式碼包裝成一個新的 Conjure client ,如此,Conjure 就可以支援 Piglet 的 interactive development 。
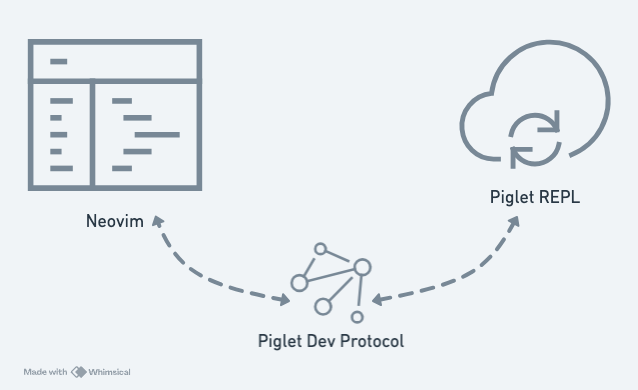
Piglet 的 Piglet Dev Protocol (PDP) 是它的互動開發協定,工作流程是:編輯器開啟 WebSocket server,Piglet REPL 以 client 角色連線進來,並且雙方透過 CBOR(Concise Binary Object Representation,一種二進位資料編碼格式)交換訊息。
下圖是 Piglet Dev Protocol 的示意:編輯器與 REPL 透過 WebSocket 溝通,中間的資料封包用 CBOR 編碼。
我一開始還一度天真地以為,我只要找一些 Neovim plugin 或是 Lua library 裝一裝就可以完成 PDP ,真的開始動手之後,才發現這比我最初想象的困難多了。
移植 websocket library
在嘗試了幾個選項之後,最接近我的需求的選項是 lua-websockets 這個 library ,其它的選項有一些可能只有實作 websocket client 又或是並非純 Lua 的實作,由於希望將來這個 conjure client 不會太難安裝,我決定使用 Luarocks 安裝的 library 就是極限了。
為了測試方便,我還安裝了一個 websocat ,這樣子我可以先專注在測試 websocket ,而不需要 websocket 與 CBOR 一起測。
不久,我成功地用 lua-websockets 造出了一個 websocket echo server 。然後,第一個挑戰就出現了:「儘管用 websocat 做的 client 端,可以順利連上在 Neovim 裡執行的 websocket server ,但是當 client 切斷連線之後,Neovim 卻會整個凍結。」
這是怎麼回事呢?問題出在 Neovim 使用 lua-websockets 本來就不太合理。lua-websocket 它提供了兩種非同步的機制:lua-ev 或是 copas (coroutine) ,然而,無論是哪一個非同步機制,它的底層都不是 Neovim 的 vim.uv 。換言之,前述的作法等於是使用了兩個事件迴圈 (一個來自 Neovim,另一個來自 lua-websockets) ,自然很容易造成上述的凍結。
了解凍結的原因之後,合理的解法也很明顯了,應該要讓事件迴圈只有一個。於是,我決定修改 lua-websockets 的底層,讓它依賴於 Neovim 的 vim.uv 。簡單地來說,我決定要 port lua-websockets 到 vim.uv 上。
在閱讀了 lua-websockets 的 source code 之後,我發現 porting 的重點,應該放在 src/websocket/server_ev.lua 即可。
這部分的 porting ,我用 LLM 來做。前後試了兩個 prompts,總算完成了可用的 websocket server.
Prompt 1
將 src/websocket/server_ev.lua 重寫,使其能夠在 Neovim 中執行。 注意:原始實作依賴四個函式庫:
ev、loop、websocket.ev_common、socket。請移除對這些函式庫的依賴,改為使用vim.uv。 …
Prompt 1 產生的程式碼大致可用,但是其中一個函數 message_io 算是嚴重的幻覺,而這個的幻覺滿合理的,因為我沒有注意到 websocket.ev_common 其實也是 server_ev.lua 的主要部分,而非外部依賴。
於是,我用了第二個 prompt 來修正這個問題。
Prompt 2
考慮 src/websocket/ev_common.lua 裡的
message_io,它依賴於 lua socket 與 lua ev 的 loop 。請重構message_io,並將該message_io裡的 sock 改成 vim.uv 裡的uv.new_tcp()的傳回值,也就是說,這個 sock 它有 read_start, write 等函式可以呼叫。 ...
CBOR 編碼與 Service Provider Interface
在 websocket 打通了之後,我立刻把訊息用 CBOR 編碼,送到 piglet 的 interpreter 去做 evaluation 。想不到,立刻失敗了。我在 Piglet 那端把 CBOR 編碼的結果用 cbor.me 網站來檢視一下,才了解失敗的原因。

問題出在:Piglet 期待的 CBOR 編碼,要在 keyword 之前,加上一個 tag 39。
由於 spc476/CBOR 的 README 寫得相對精簡,再加上我對 Lua 很不熟,不熟到我連 setmetatable 都看不太懂。於是,我陷入了卡關:「到底要怎樣呼叫 Lua 的 cbor library,才有可能順利地插入 tag 39 且讓 tag 39 修飾 msg 裡的 keyword ?」
在開發過程之中,我問了 LLM 幾次,LLM 也給了幾種不同的呼叫法,都不正確。
總之,後來,我捨棄了 LLM ,回頭慢慢去閱讀 README 和 Lua 的 API ,總算想出了解法。
(local cbor (require :org.conman.cbor))
;; 定義一個 keyword 函數,它可以用來註冊 __tocbor 函數
(fn keyword [s]
;; keyword changes the string $s => `:$s`
;; and return a table with the content is `{:v $changed_string}`
;; and the returned table has a `__tocbor` function in its metatable."
(let [t {:v (.. ":" s)}
mt {:__tocbor (fn [self]
(cbor.TAG._id self.v))}]
(setmetatable t mt)))
;; 宣告一個 msg,其中,它的 key 要用上面的函數修飾。
(local msg {(keyword "op") :eval (keyword "code") "(+ 1 1)"})
;; 將整個 msg 做 cbor 編碼,cbor.encode 會去呼叫 __tocbor 函數。
(cbor.encode msg)關於這個卡關,事後我有做一些反省。首先,由於 LLM 只能做模式比對,像 Lua 這種小眾的語言或是 README 寫得比較精簡,LLM 無法給出答案還滿自然的。
另外,CBOR 這類函式庫本身採用「可延展的方式」設計,所以它的內部實作有一段是鬆耦合設計。
鬆耦合設計如果是在物件導向程式語言,包含 Java, Lua ,則常會透過 Java 的 interface 或 Lua 的 metatable 來實作,它常常會是一種 Service Provider Interface。日後,如果要替換鬆耦合所接合的舊模組,我們只要開發新的模組且該新模組有實作相同的 Java interface 或是註冊一樣的 Lua metatable 函式,新模組就可以順利替換舊模組。
也因此,日後我如果再次遇到類似的情況,我應該這樣子思考:
欲使用之函式庫功能,是否可能是函式庫的設計者最初沒有覆蓋到的情境?(CBOR 的 tag 39 就是範例,它不是一般情況)
如果是的話,那函式庫的設計者是否已經對這種情況,留下了 Service Provider Interface,讓使用者日後可以做出修改?(Lua 的 metatable
__tocbor就是這個介面)是否我可以循著 Service Provider Interface 去對函式庫注入一段我寫的程式碼?(我最後就是透過 metatable 來插入自訂編碼邏輯)
註冊檔案型態 (filetype)
在 websocket 與 CBOR 都可以運作之後,我設法將手上的程式碼塞入一個 Conjure client template 裡。
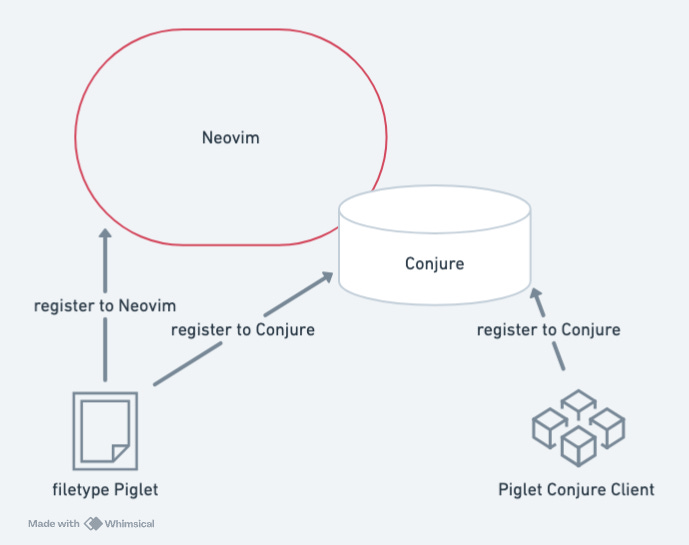
本來我滿心期待,在我將新寫的 Piglet client 註冊給 Conjure 之後,這個新的 Conjure Piglet client 就會立刻活起來,結果沒有。參考下圖,因為我需要註冊的地方其實有三處:
讓 Neovim 可以辨別 Piglet 這個 filetype 。
讓 Conjure 會對 Piglet file 啟動。
讓 Conjure 用 Piglet client 來處理 Piglet file 。
終於,新的 Conjure Piglet client 就這樣子做出來了,雖然只有基本的 eval-str 功能。
結語
在開發的過程中,我算是大量地閱讀了 Conjure 與 Piglet Emacs Plugin 的 source code 。我大致是這樣子閱讀:
不求一次了解全部,先片段片段地理解。
設法循著 code execution 的軌跡來閱讀。
依賴著「字串搜尋功能」跳著讀。
由於 Conjure Fennel client 並不支援定義跳轉,這讓我的第三步驟又痛苦了許多,也許我之後應該試著把 Conjure Fennel client 的定義跳轉設法做出來。(註:其實 Fennel 語言有基於靜態分析的定義跳轉的功能,只是必須搭配 Language Server Protocol 使用,而非 Conjure 內建。)