
Datomic 作為一種高階資料庫
Datomic 帶來生產力,因為它是一種高階資料庫。

20 多年以前,當我剛開始學習程式語言的時候,曾經從書上看到一句話。
C 語言是一種高階語言
而我真正領悟到 C 語言有多高階時,則是在數年之後,當我在大學的課堂上學到了組合語言,連寫一個迴圈都要使用 jump 這種指令時,我才深深感受到 C 的高階。儘管如此,在我多數的職涯裡,我都覺得 C 語言低階到不行,因為我不想處理記憶體的 malloc 和 free 、不想處理指針。在往後的職涯,我學了許多程式語言。其中,Java 比 C 高階的多,因為 Java 提供了記憶體回收 (garbage collection) 功能; Clojure 又比 Java 更高階,因為 Clojure 提供了不可變容器類別 (immutable collection types)。
高階並不是指功能多,有時候還剛好相反
高階並不是指功能多,而是語意更高階,所以它往往限制或是甚至不提供低階的語意。高階的語意可以讓你在使用時,讓你講出目的就好,不用一一去指定所有的執行細節,細節將由機器幫你代勞。有一些細節由於你實在太容易搞砸了,還會加上限制,不准你直接操作它。
在寫 C 語言的時候,多數時候你被強烈不鼓勵使用 jump 指令;在寫 Java 的時候,你無法直接操作指針;在寫 Clojure 的時候,你被強烈建議不要使用可變容器類別 (mutable collection types)。
高階語意通常也會付出機器效能的代價。JVM 的記憶體回收顯然會使用額外的記憶體;Clojure 伴隨著不可變容器類別當然也在記憶體用量方面,更勝 Java 一籌。還有,Clojure 的啟動時間更是遠遠超越了 Java ,突破了人類耐心的上限,甚致導致了 Babasha 這樣子專門為 shell 設計的解決方案的出現。
高階通常意謂著拿機器的效能去換取軟體開發者生產力,而由於摩爾定律的存在,機器的效能會自動隨時間增加,這筆交換通常非常合算。
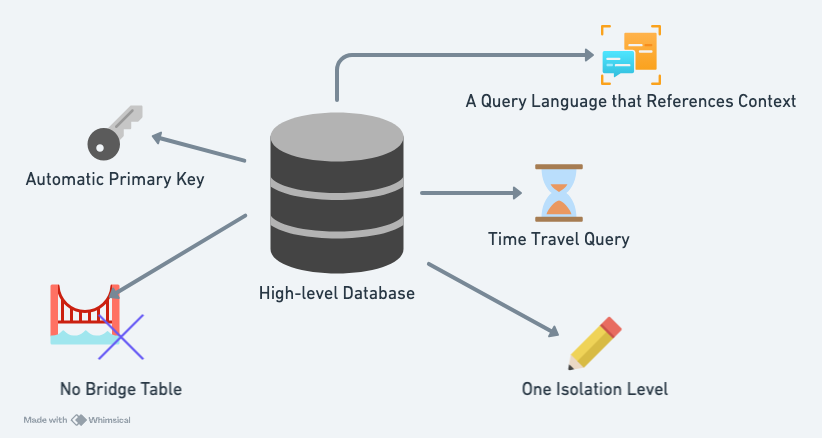
Datomic 高階在哪?
在我使用 Datomic 的經驗裡,我至少在四個方面體驗到 Datomic 高階之處。
資料定義語言 (DDL)
主鍵
多對多的關係
交易隔離層級 (Isolation Level)
可回溯的查詢 (Time Travel Query)
可引用上下文的查詢語言
資料定義語言 - 主鍵
在使用 SQL 資料庫時,我常常為了該如何設計 SQL 資料表的主鍵 (primary key) 而困擾不已。每次遇到這種問題,第一個要考慮的就是:
要用自然鍵 (natural key) 來當主鍵嗎?自然鍵是業務規則 (business) 中所擁有的一個或多個的資料屬性。這個作法在初期很省事,但是不見得在往後也是如此。
要用代理鍵 (surrogate key) 來當主鍵嗎?這種主鍵可以與業務意義 (business meaning) 解耦,將來修改的彈性較高。此外,部分的表 (table) 因為它是某個資料實體的一小部分,它沒有可以做為自然鍵的資料屬性,這種表就必須使用代理鍵。
如果說決定了要使用代理鍵,接下來的問題就是,該怎麼決定代理鍵的資料型態:
遞增整數
字串 (UUID)
然後,又要考慮會不會有列舉攻擊 (enumeration attacks)、效能夠不夠好?到底是要使用可迴避列舉攻擊的整數、還是要選擇有加強效能的 UUID ?
Datomic 幫你做了主鍵的決定。在 Datomic 的世界,主鍵就是資料實體編碼 (entity id),就是這麼簡單。
資料定義語言 - 多對多的關系
在 SQL 資料庫,當我們需要建模 (model) 多對多的關係 (many to many relationships) 時,我們往往必須設計一張橋接表 (bridge table) 。
在 Datomic 資料庫,我們不需要設計橋接表,因為我們可以把 :db/cardinality 設定成 :db.cardinality/many ,意思是:這個欄位綱要它可以『一對多』。 :db.cardinality/many 這種特性,它一方面因為省去了橋接表讓語意更加高階之外,同時也讓「一對多」與「多對多」的語法看起來一致得多
交易隔離層級
SQL 資料庫有四種交易隔離層級
未提交讀 (Read Uncommitted)
提交讀取 (Read Committed)
重複讀取 (Repeatable Read)
序列化 (Serializable)
多種隔離層級為的就是讓我們在處理交易時,可以達成更高的效能。相較之下,Datomic 只提供了一種交易隔離,也就是序列化 (Serializable) 。功能變少了的同時,我們需要操心的事也變少了。
可回溯的查詢
傳統的資料庫的狀態就像是寫在一般的檔案裡,一旦寫入了,就無法回到上一個狀態。而 Datomic 不同,它的狀態就像是寫在一個 git repo 裡,要回到上一個狀態輕而易舉,透過可以回溯資料庫狀態的查詢 (as-of 查詢) 即可。
可引用上下文的查詢語言
在寫 SQL 的查詢時,如果我寫到那種要 join 很多張表的查詢,之後我通常都會有閱讀困難:那種 SQL 語句實在太長了,人類的腦子實在很難處理這麼長的句子。人類使用的自然語言,相較於 SQL 查詢,往往是許許多多的短句。然而,短句為何又可以傳遞複雜的概念,這跟上下文有關。我們在理解自然語言時,我們並不是把一個句子單獨地來做理解,而是搭配它的上下文來做理解。而 Datomic 的查詢語言 Datalog 有一個 Rules 機制,它可以很巧妙地為查詢語句注入上下文。
考慮下方的 Datalog 查詢,它要找出『魔鬼終結者 (Terminator) 這部電影的演員名字』
[:find ?name
:where
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title "The Terminator"]]想象一下,如果當查詢之中的一小部分 (即用來『從電影名查詢演員名』的一小段) 總是反復地在不同的查詢中使用時,是否可以有什麼機制可以讓我們不需要一次又一次地重寫下方這段程式碼呢?
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title ?title]有的,這個抽象機制叫做規則 (Rules)。於是,我們可以利用 Datomic Rules 將上述的查詢改寫成如下的新寫法:
;; The rules we defined
[(appear ?name ?title)
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title ?title]]
;; re-written Datolog Query
[:find ?name
:in $ %
:where (appear ?name "The Terminator")]在這個寫法裡,appear 這條邏輯規則在 Datomic 資料庫上呈現出了「演出的定義」。一旦查詢引擎應用了這條邏輯規則,自然可以推導出「演出」這種新知識。
此處所寫的規則本身就是一種可以傳遞上下文 (context) 的工具。查詢語言一旦可以引用上下文,就更加近似於人類的自然語言,變得更加精簡。
想像一個新的對話
你推荐 Datomic 給你的老闆,他問你,它有什麼好處?何以見得?
你回答:「它帶來生產力,因為它是一種高階資料庫。」
我期待他會問你,「什麼叫做高階?」
如果細心巧妙地進行的話,這段開啟的對話,有機會引導你順利地在公司內推動使用高階資料庫。精明的生意人也許不會記得、且難以理解資料庫的種種細節,但是,高階等同於拿機器的算力換成腦力。拿便宜的換貴的,這就是生意人最善長搞懂的事。
nice post