
圖學檢索增強生成 (GraphRAG)
傳遞上下文的概念除了在 LLM 的應用有影響之外,在一般軟體開發也一樣重要。

最近我看了一篇與 RAG 相關的論文。它的大意是:「直接拿 LLM 來搭配 SQL 資料庫使用的話,準確度只有 16% 。同樣的測試資料,如果在 SQL 資料庫之前加上了一層圖學資料庫來提供上下文 (context),準確度可以大幅提高到 54%。」
下方兩張圖是論文裡的實驗架構:
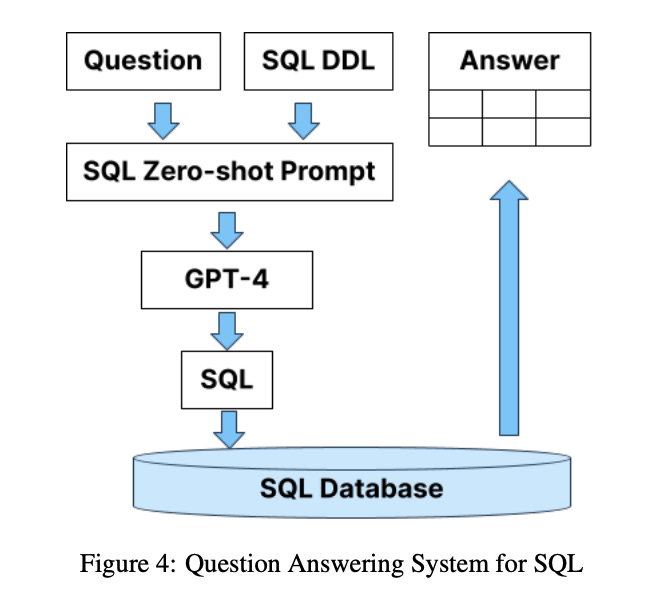
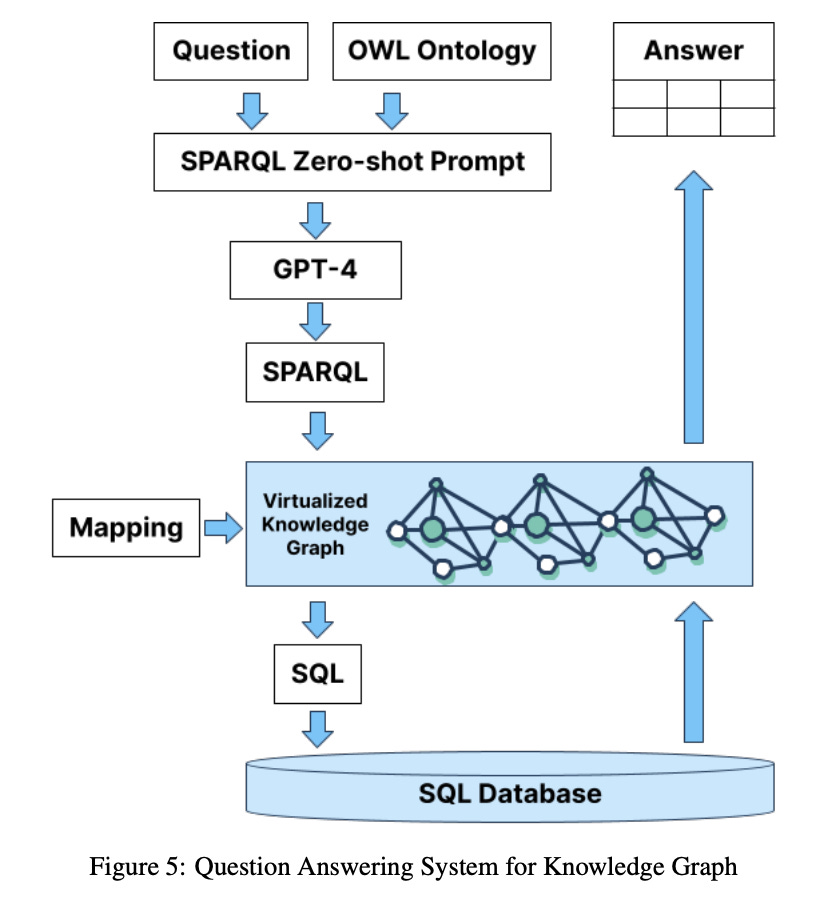
由論文的實驗架構與結論自然可以推得:所以 ontology 至關重要。
我曾經有研究圖學資料庫一小段時間,還考了一張 neo4j 的証照。僅管如此,不知為何,每次看到 ontology 這個詞彙出現時,就有一種頭腦打結的感覺,總覺得很不容易理解什麼是 ontology ?同時,上下文 (context) 也一樣讓我覺得抽象到不行。
從 Datomic 的 Rules 來理解 ontology
前些日子,我寫了一系列介紹 Datomic 的文章,邊寫邊想,突然覺得一旦做了類比之後, ontology 也不是那麼難懂了。
如果讀者把 Datomic 相關文章看一看的話,可以發現三件事:
Datomic 的 Datalog 查詢,與 SPARQL 一樣都是 RDF 的形式。
Datomic 的 Datalog 查詢,表現力至少等價於 SQL 。 而且 Datomic 本身就可以做為 OLTP 資料庫使用。
Datomic 的 Rules 部分,在 SQL 裡沒有對應的存在。
有趣的事情是,我查了 OWL ontology ,看到了一句話:「OWL 支援推理功能,可以讓查詢引擎根據定義的邏輯規則推導出新知識。」咦,這不就是 Datomic Rules 的功能嗎?
Datomic 的實際例子
看個實際的例子吧。像下方的 Datalog 查詢,它要找出『魔鬼終結者 (Terminator) 這部電影的演員名字』
[:find ?name
:where
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title "The Terminator"]]查詢之中的一小部分,用來『從電影名查詢演員名』的,總是反復地在不同的查詢使用,是否可以有什麼抽象機制可以讓我們不需要一次又一次地重寫下方這段程式碼呢?
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title ?title]有的,這個抽象機制叫做規則 (Rules)。於是,我們可以利用 Datomic Rules 將上述的查詢改寫成如下新的寫法:
;; 我們定義的規則
[(appear ?name ?title)
[?p :person/name ?name]
[?m :movie/cast ?p]
[?m :movie/title ?title]]
;; 改寫後的 Datalog 查詢
[:find ?name
:in $ %
:where (appear ?name "The Terminator")]在這個寫法裡,appear 這條邏輯規則在 Datomic 資料庫上呈現出了「演出的定義」。一旦查詢引擎應用了這條邏輯規則,自然可以推導出「演出」這種新知識。
對軟體開發者、或是負責寫查詢的人來說,把「有用規則」與「沒有用規則」比較的話,當然是「有用規則」會讓查詢好寫得多、讓查詢容易理解得多。
在上述的例子裡,我們也可以想成,此處所寫的規則本身就是一種可以傳遞上下文 (context) 的工具。(註:上下文也可以稱之為「語境」。)
結論
我有多查了一些資料, OWL ontology 與 Datalog Rules 還是有些差異,並不等價,但是都可以提供上下文。而上下文在人與人之間的自然語言溝通有大量使用,僅管我們可能渾然不覺。正因如此,當人要跟資料庫溝通時,上下文自然必須加入,才會讓溝通順暢。
更進一步,已知人類就是有在溝通時使用上下文的習慣,查詢語言的設計如果有一個機制可以將上下文加以編碼,類似 Datalog Rules ,這對語言的可讀性、易用性,將會有極大的助益。