
函數式資料轉換
函數式資料轉換 (functional data transformation) 比傳統的資料轉換更有效率、而且可以取代許多不必要的 stored procedure。

一年多前,我犯下了一個錯誤:當我在解釋為何現代資料棧 (modern data stack) 可以大幅提高產出時,我所講的理由是:因為應用了 ELT 取代 ETL 。ELT 確實是原因之一,但是,並不是完整的原因,還有一個更重要的原因:因為應用了函數式資料轉換 (functional data transformation) 。
前陣子,我去拜訪了一位朋友,他已經從事 DBA 工作十年以上。與他交流技術時,他告訴我,他很久以前就知道利用 ELT 取代 ETL 來提高產出,而且,他都在資料倉儲 (data warehouse) 之內,寫儲存程序 (stored procedure) 來做複雜的資料轉換。
當我聽到他講,他主要透過寫 stored procedure 來做複雜的資料轉換 (data transformation) 時,我腦中所浮現的畫面是長成下圖:
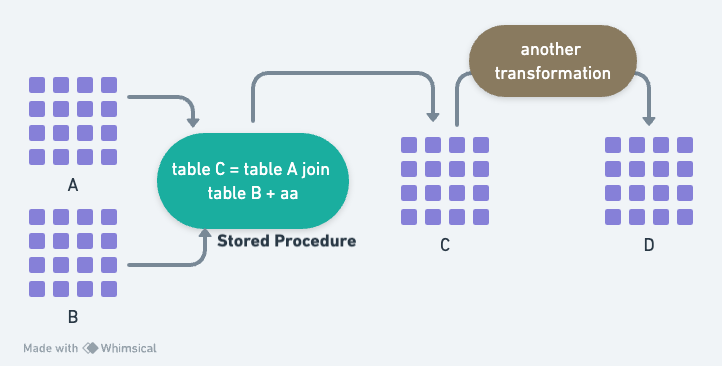
上圖是在描述,在資料倉儲之內,資料轉換 (data transformation) 如何實現。在圖裡,原始資料是 A 與 B 這兩張表,完成轉換的資料是 D 表。綠色、黃綠色的兩個橢圓形是 stored procedure 。C 表是資料轉換過程中的暫存表。
這個資料轉換作法是把資料轉換寫在 stored procedure 裡,並且搭配一些暫存表。
這些 stored procedure 裡,通常會有 SQL query 與命令式編程的邏輯。
SQL view 取代 stored procedure 與暫存表
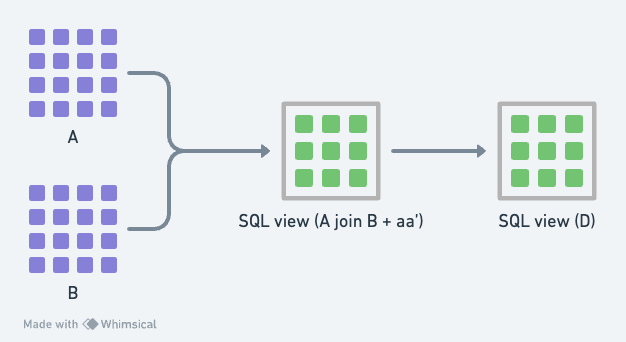
這張圖是現代資料棧裡典型的資料轉換的示意圖,我稱它為函數式資料轉換 (functional data transformation) ,看起來與上圖彷彿沒有太大的分別,然而,主要的差異點有二:
資料轉換不是寫在 stored procedure 裡,而是用 SQL query 取代命令式編程的邏輯,並且用 SQL view 來封裝 SQL query。(註1)
不需要使用暫存表。
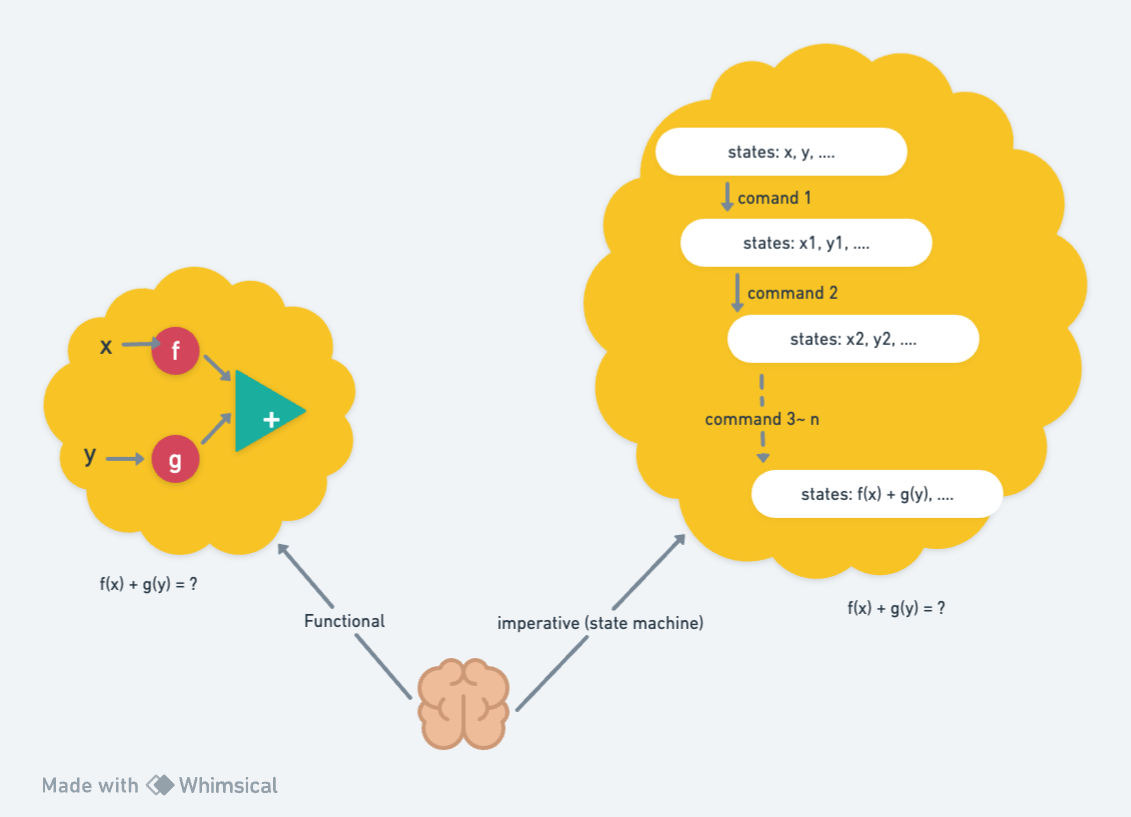
為什麼這樣子就可以稱之為函數式資料轉換呢?首先我要先定義一下『函數式』一詞,定義是:「人腦對於編程的想象與寫作,是透過反覆地組合 (compose) 函數達成,即『數學函數運算』。」相對於函數式編程的概念,傳統的命令式編程則是對一塊記憶體反覆地去改變記憶體的內容來達成,即『有限狀態機運算』。
函數式 vs 命令式
有一定電腦科學基礎的讀者可能很困惑:「電腦內部的架構,難道不是 Von Neumann model 嗎?計算的本質,不就是透過對一塊記憶體反覆地去改變記憶體的內容來達成嗎?」
是的,那是電腦的部分,並不代表人腦對於編程的想象與寫作也一定如此。
底層的執行與實作不一定完全等價於人腦的想象與寫作,比方說,當我們寫的程式碼是 1.23 / 2 時,人腦想象的邏輯是數學上的概念。但是,由於多數的時候 1.23 是使用浮點數,電腦在執行時是使用浮點數的除法,它的實作會跟數學上的概念不完全等價,只是近似。
順著上頭的例子來想的話,編程應該也跟數學函數運算也不會差很多吧,畢竟程式語言裡也有數學的加減乘除?其實,常常是差滿多的。特別是,當我們使用傳統的命令式編程的寫作方式來寫的話,就算寫的是高階語言,人腦想象的邏輯還是比較接近於「有限狀態機運算」。
以 i = i + 1; 這段程式碼為例,如果我們把 = 理解成數學的『等於』符號的話,這個寫法在數學上完全不合理,顯然這不是數學函數運算。實際上,這段程式碼裡的 = 符號之語意是指定運算 (assignment operation) ,也就是改變記憶體的內容。上述這種帶有指定運算的程式碼在傳統的命令式編程非常地普遍,這同時也是多數學生剛學習程式設計時,最初學到的程式設計思考方式。
SQL view 的作法,不用處理資料回填且讓除錯變得容易。
SQL view 看起來就像是表 (table)。人在思考時,看成是表的話,就可以把它想象成是『靜態的數值』。而實際上,SQL view 在運作時,會轉換成 query,也就是『表達式』。靜態的數值與表達式可以互相代換的這個性質,可稱之為「引用透明性」,這是函數式編程的重要性質。(註2)
讀者可能會問:「難道 SQL view 與第一張圖中的暫存表,真的有如此大的差異嗎?怎麼看,第一張圖中的暫存表,也像是跟 SQL view 差不多啊?」
不,它不一樣。因為一旦原始的表 A、表 B 發生變動時,比方說,插入十個新的列 (row) 時,暫存表如果還沒有更新,這個瞬間就不相等了。而這個瞬間就是傳統資料轉換需要做資料回填 (backfill) 的時刻。
如果問題是出在暫存表上的話,那刻意把邏輯全部刻意寫進 stored procedure 裡,完全不使用暫存表,不就沒有上述資料回填的問題了嗎?
沒有資料回填的問題,但是會造成新的問題:難以除錯。當 stored procedure 裡有任何的邏輯錯誤時,因為所有的中間計算過程都藏在 stored procedure 裡頭,所以沒有辦法透過檢查暫存表的資料正確性,來大概定位出錯誤的位置,也因此大幅增加除錯的困難度。
結論
函數式資料轉換 (functional data transformation) 相對於傳統的資料轉換作法,有容易除錯與不用處理資料回填的優點,可以取代許多不必要的 stored procedure,也因此可以讓產出大幅地提升。(註3)
註:
在 SQL:2003 之後,由於有了 window function 等眾多的新功能,光是透過 SQL query 已經可以實現絕大多數的命令式編程邏輯。
所謂的引用透明性是指:「若一個表達式在被其相應的值替換時能不改變程式的行為,則該表達式是引用透明的。」考慮如下的程式:
f(x) = (4 + 5) + x,我們可以把(4 + 5)這個表達式改成9這個相應的值,於是原本的程式變成了f(x) = 9 + x。改變前後,f(x)程式的行為是完全等價的,這樣子我們可以說(4 + 5)滿足引用透明性。引用透明性很容易在數學運算裡滿足,甚至不滿足反而很奇怪。然而,當有 assignment operation 出現時,即不是數學運算而是有限狀態機運算時,引用透明性就很容易不滿足了。在本文中,比較兩種不同的資料轉換 (函數式 vs 傳統 stored procedure 搭配暫存表) 的概念圖是化簡的模型,還沒有討論到資料工程裡需要管理的資料譜系 (data lineage) 等議題,但已經足以說明函數式作法的優異之處。