
跳轉定義
程式語言可以算是結構化資料嗎?

在上一篇裡,我開發了一個 Neovim Plugin ,專門用於 Piglet 的互動式開發。由於,既有的 Emacs Plugin 總共實作了兩個功能:
eval-str:對字串求值
jump-to-definition:跳轉定義
我在完成 eval-str 之後,也接著開始研究「跳轉定義」如何設計。
運行環境
研究的過程中,我發現了一件有趣的事:像 Clojure 語言的跳轉定義,它是使用運行環境後設資訊;而多數程式語言的跳轉定義,則是基於靜態分析而開發的。
這是怎麼說呢?
看一個小小的實驗吧:
user=> (def a 13)
#'user/a
user=> (meta #'a))
{:line 1, :column 1, :file "NO_SOURCE_PATH", :name a, :ns #object[clojure.lang.Namespace 0x130a0f66 "user"]}在 Clojure 程式語言裡,任意定義一個新的值、或是函數之後。只要使用 meta 函數去查閱它的後設資訊,就可以得到它被定義的檔案、在檔案中的位置、模組名稱等資訊。
換言之,如果要在編輯器插件裡實作跳轉定義,這超簡單的。插件送出「對變數的查詢」,然後,直譯器用 meta 查個資料,傳回給插件就差不多完成 90% 了。
靜態分析
然而,多數的程式語言並沒有像 Clojure 一樣,在運行期間為每個變數提供豐富的後設資訊。也因此,可行的跳轉定義實作方式是:
先解析程式碼,變成語法樹 (詞法分析 && 語法分析)。
從語法樹進一步做出語意分析。
當收到查詢時,從上述分析的結果裡傳回後設資訊。
儘管,Fennel 語言本來就已經有基於 LSP (language server protocol) 的跳轉定義實作了,我基於好奇心,決定自己動手,設法直接將 Fennel 語言的跳轉定義功能做進 Fennel Conjure Client 裡。
那該怎麼解析程式碼呢?
我用了 treesitter 函式庫來做這件事。下圖中的左邊是 treesitter 生成的語法樹。
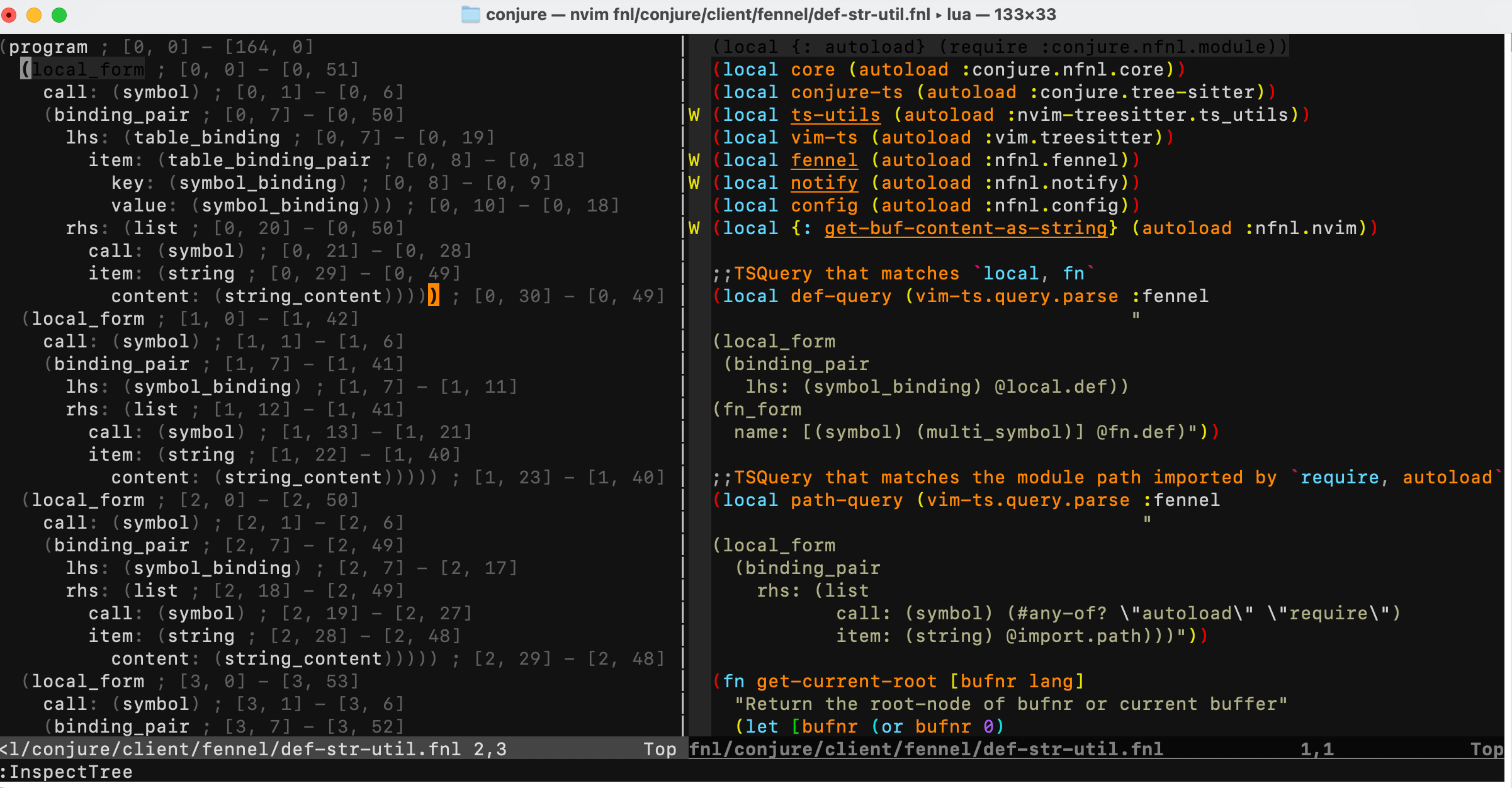
結構化資料
「程式碼是結構化資料嗎?」邊做這個專案,我就邊想這個問題。
首先,人類的語言也可以做解析。形式語言學 (formal linguistics) 可利用語法樹來解析句子的結構。例如:「我是在浪費我的時間。」人類的語言做完了解析之後,它變成了一個可以查詢的結構。
S(句子)
├── NP(名詞短語):我
├── VP(動詞短語)
├── V(動詞):是
├── PP(介詞短語)
├── 在(介詞)
├── VP(動詞短語)
├── V(動詞):浪費
├── NP(名詞短語):我的時間舉個例子:「牛奶不如果汁好喝」算是使用『如果』一詞的造句嗎?這題不容易讓電腦依賴單純的字串比對來回答吧?有語法樹的話,電腦也可以解答了。
程式碼不也是一樣嗎?做了語法樹的解析之後,它就變成了一個可以查詢的結構。
結語
從這角度看,程式碼本身就是一種帶有隱性結構的資料,而這也是為什麼我們能對它進行靜態分析。不論是基於運行環境的動態後設資訊,還是透過靜態解析產生的語法樹,這些方法都讓我們能像應用資料庫一樣,以程式化的方式來理解、操作和查詢程式碼。如果 LLM 對程式碼的理解,也可以搭配這些隱性結構,機器是否也能更加深入地理解程式內的邏輯呢?